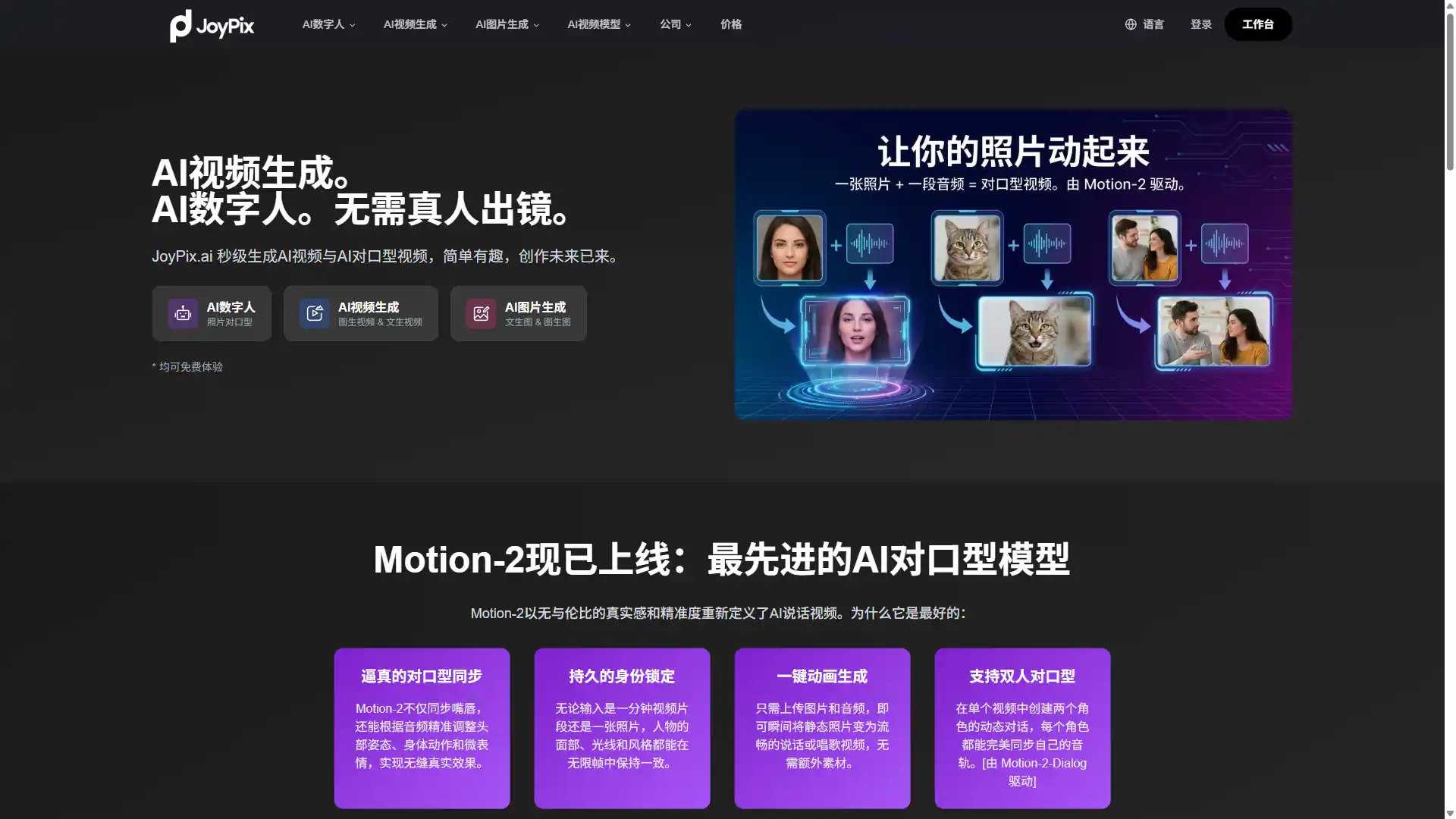
你见过 AI 对口型的翻车现场吗?
打开任何一个 AI 口型同步工具,上传一张人像照片,配上一段音频,点击生成——
出来的视频里,人物的嘴唇确实在动,和音频勉强对得上。但整个脑袋像被钉在墙上一样纹丝不动,眼神死气沉沉,身体僵硬得像个蜡像。你看着这张「会说话的照片」,只觉得诡异。
这就是 AI talking video 行业的尴尬现状:口型对上了,但人不像活的。
嘴唇动只是说话的最低配表现。真实的人类说话时,头部会微微晃动,眉毛会跟着情绪起伏,肩膀会有呼吸感的起伏,甚至整个身体姿态都在参与表达。只动嘴不动身,那不叫说话,叫腹语。
JoyPix 的 Motion-2 模型,终于把这个问题当回事了。
👉
Motion-2 做了什么不一样的事?
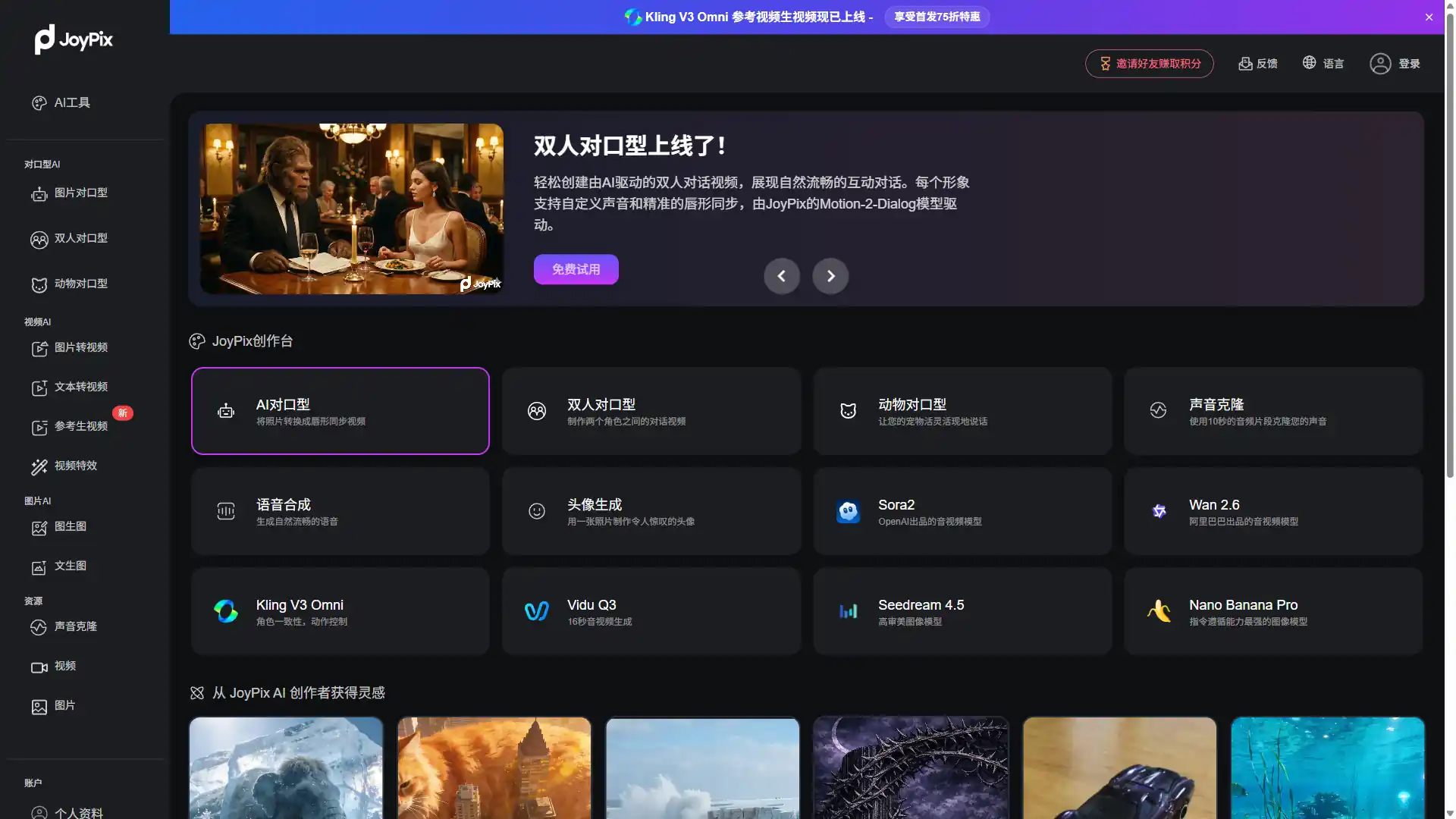
JoyPix 把自家最新的口型同步模型命名为 Motion-2,不是随便叫的。「Motion」这个词就是它的核心主张——不只是口型同步,是全身动势同步。
具体拆开来看,Motion-2 做了三件竞品没做好的事:
第一:True-To-Life Lip Sync——不止动嘴
传统 AI 口型同步只做一件事:让嘴唇开合跟音频节奏对齐。Motion-2 在此基础上,同步驱动头部姿态、身体姿势和微表情。
什么意思?当你的人物说到强调的地方,头部会自然前倾;说到感叹句,眉毛会微微上挑;说到低沉的内容,肩膀会有轻微的收缩感——这才是真实的人类说话方式。
只动嘴的视频让人发毛。全身都在动的视频,才让人相信这是真的。
第二:Everlasting Identity Lock——人脸不会跑
这是所有 AI talking video 工具的通病:视频超过 10 秒,人物的脸就开始「漂移」。光照变了、五官比例变了、甚至性别都模糊了——同一个角色,一秒是张三,下一秒变李四。
Motion-2 的 Identity Lock 机制,不管你喂给它的是 1 分钟的视频素材还是仅仅一张照片,都能在无限帧数内保持人物面部、光照和风格的一致性。
你的人物从第一帧到最后一帧,是同一个人。 这听起来应该是基本要求,但在当前的 AI talking video 领域,能做到的产品凤毛麟角。
第三:One-Shot Animation——一张照片就够了
很多 AI 数字人工具要求你上传一段 3-5 分钟的原始视频素材做训练,才能生成口型同步的结果。问题是——你手里不一定有那段视频。
Motion-2 的 One-Shot Animation 功能:丢进去一张照片+一段音频,直接生成说话或唱歌的完整视频。 不需要额外素材,不需要预先训练,不需要准备各种角度的底片。
有一张正面照就够了。没有正面照?AI 生成的脸也行。
不只是口型同步——JoyPix 的完整工具箱
如果 JoyPix 只是一个口型同步工具,那它顶多是个「更好的 D-ID」。但 JoyPix 显然想做更多:
AI Lip Sync——口型同步,Motion-2 驱动
核心功能,前面已经讲透了。多语言音频输入,自动生成全身动势同步的说话视频。
AI Talking Video——对话视频,两人同框
JoyPix 支持双角色对话视频生成——这在同类产品里不多见。不是简单的「两个人各说各话然后拼在一起」,而是在同一个场景中,两个人物有交互感的对话视频。
做播客对口型、双人对话短视频、角色扮演场景?这个功能直接省掉你一半的工作量。
Image to Video & Text to Video——图片/文字生成视频
上传一张图片,描述你想让它怎么动,AI 帮你生成视频。或者直接输入文字描述,从零开始生成。
不是口型同步的附属品,是完整独立的视频生成功能。
AI Image Generator——文字生图+图片编辑
JoyPix 还内置了 AI 图像生成和编辑功能。Text to Image 生成你需要的素材图,Image Edit 做精细化调整。
一条龙的意思是:你不需要先去 Midjourney 出图,再跑到 D-ID 做口型,再去剪映加字幕。在 JoyPix 里,从出图到出视频,一个平台搞定。
Free Voice Cloning——免费声音克隆
上传一小段你的声音样本,AI 克隆你的声线,然后用你的声音说任何话。做个人 IP 的内容批量生产,或者给数字人配上统一的声音,这个功能是刚需。
而且 JoyPix 把 Voice Cloning 放在了免费功能里——同类产品里,声音克隆通常是付费高级功能。
竞品对标:JoyPix 凭什么站住脚?
vs HeyGen:巨头做的不一定是最好的
HeyGen 是 AI 数字人赛道里知名度最高的产品,融资多、用户多、模板多。但知名度高不等于每个功能都强。
HeyGen 的口型同步,老实说,还是停留在「只动嘴」的阶段。 头部微动有一点,但身体的自然动势几乎没有,更别提微表情了。看久了,人物还是有一种「照片贴在弹簧上」的违和感。
JoyPix Motion-2 的全身动势同步是降维打击。 你让两个产品各生成一段 30 秒的说话视频放在一起看,差别肉眼可见——HeyGen 的人物是「说话的照片」,JoyPix 的人物是「在说话的人」。
另外,HeyGen 的定价不便宜,Creator 计划 29 美元/月,Business 计划 89 美元/月起步。JoyPix 可以免费开始使用,Voice Cloning 也免费——试错成本完全不同。
vs D-ID:老牌选手,能力卡在上一代
D-ID 是 AI talking video 的开创者之一,Creative Reality Studio 在行业里有一定口碑。
但 D-ID 的口型同步质量近两年几乎没有突破性更新。嘴唇能对上,但面部表情僵硬、头部几乎不动、长视频人脸漂移严重——这些都是 2023 年就该解决的问题,到 2026 年还在。
Motion-2 的 Identity Lock 直面的就是这个痛点:长视频人脸不漂移,而且全脸+身体都有自然动势。D-ID 的技术积累在走下坡路,JoyPix 在走上坡路。
vs Puppetry:模式类似,深度不同
Puppetry 的定位和 JoyPix 很像——上传照片、输入脚本、生成说话视频。支持 500+ 声音、65+ 语言,在多语言覆盖上有优势。
但 Puppetry 的核心能力停留在「Talking Head」——会说话的脑袋。身体动势?没有。微表情?很有限。双人同框?不支持。
JoyPix 的 Motion-2 不是做一个更好的 Talking Head,是重新定义了 AI 口型同步应该做到什么程度。 从「头在动」到「人在动」,这一步看着不大,体验天差地别。
vs HeyGem:开源免费 vs 商业级体验
HeyGem 是国内开源的数字人方案,可以本地部署,完全免费——对于有显卡、会配置环境的开发者来说,性价比极高。
但 HeyGem 需要本地部署(8G 以上显存),配置过程对非技术用户不友好。而且开源方案在口型同步的精细度和稳定性上,跟 JoyPix 这种专注打磨单一产品的商业方案比,还是有差距。
如果你是开发者,想在自己的服务器上跑数字人,HeyGem 是好选择。如果你是内容创作者,只想快速出高质量视频,JoyPix 开箱即用更实际。
谁应该用 JoyPix?
内容创作者——做视频不用出镜
你做短视频、做自媒体,但不想露脸。以前你只有两个选择:配音+素材混剪(没有个人 IP 感),或者用传统数字人(僵硬得像电子遗像)。
JoyPix 的 Motion-2 让你的数字人真正像在说话、像在表达。观众看到的不是一张会动的照片,是一个有温度的讲述者。
营销团队——批量生产多语言视频
你需要把同一个产品介绍视频做成 10 种语言版本。传统做法:找 10 个配音演员,或者用 TTS 合成声音然后手动对口型。
JoyPix 的路径:一段原始视频 + 10 种语言的音频 → 10 段口型完美同步的多语言视频。声音克隆功能还能保证所有语言版本都是「同一个人在说话」。
从一周的工作量压缩到一下午。
教育从业者——让课件里的人物活过来
在线课程、培训视频、企业内训——大量需要「人出镜讲解」的场景。但你不可能为每门课都请真人录制。
JoyPix 的 One-Shot Animation:一张讲师照片 + 讲稿音频 = 完整讲解视频。换一门课,换一段音频,同一个「讲师」继续讲。Identity Lock 保证他从头到尾长得一样。
独立开发者——给产品做个会说话的 Demo
你做了一个 App,想录个介绍视频。但你对出镜有抵触,而且录了 N 条都不满意。
JoyPix:用 AI 生成一个代言人形象,输入你的产品介绍文案,一键生成口型同步的产品介绍视频。零拍摄,零后期,零社恐。
写在最后
AI talking video 这个赛道,2023 年 D-ID 开了个头,2024 年 HeyGen 把它推向主流,2025 年一大堆跟风产品涌入。但直到 2026 年,绝大多数产品的口型同步还停留在「嘴唇对上了就行」的水平。
JoyPix Motion-2 是第一个认真回答「人说话时到底该是什么样」这个问题的产品。
口型同步只是说话的最低标准。真实的说话是全身参与的表达——头在动、眉在挑、肩在转、身体有呼吸感。Motion-2 朝这个方向迈出了实质性的第一步。
而且 JoyPix 可以免费开始,Voice Cloning 免费,核心功能都开放体验——这意味着你没有任何理由不去试一下,亲眼看看 Motion-2 和传统口型同步的区别。
别再接受「只动嘴的数字人」了。2026 年了,该让 AI 里的人真正活起来。
👉
「AI talking video,终于不只是嘴在动。」
相关文章



