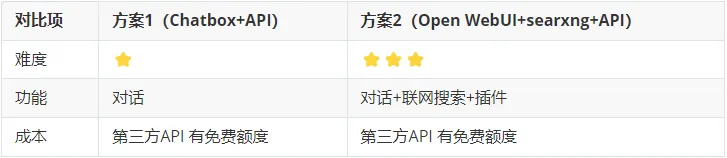
📌 方案对比
方案1:快速对话(Chatbox版)
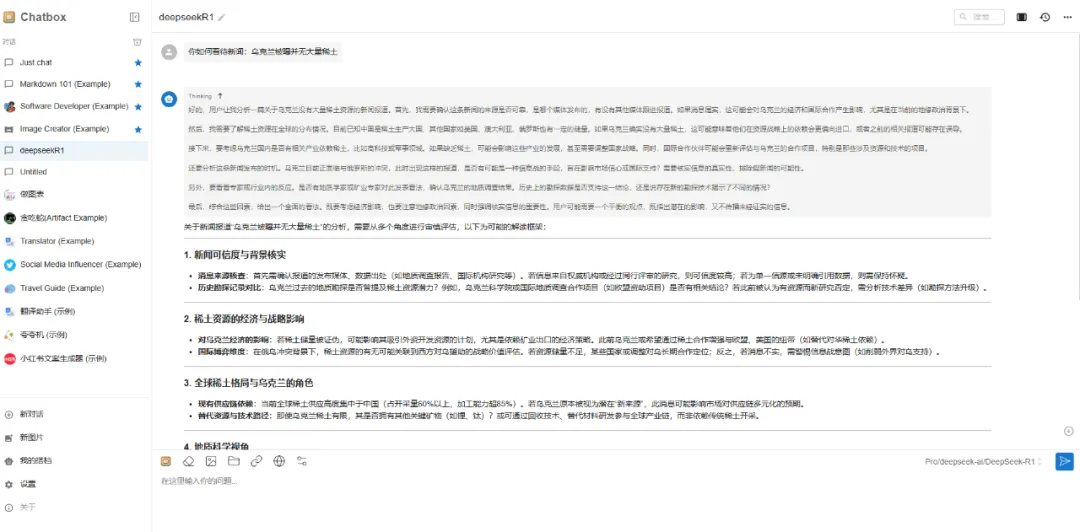
🎯 效果预览
Chatbox里不是所有的模型都支持联网搜索,基础的对话是没有问题的。
🛠️ 准备工作
-
注册账号(任选一个)
-
-
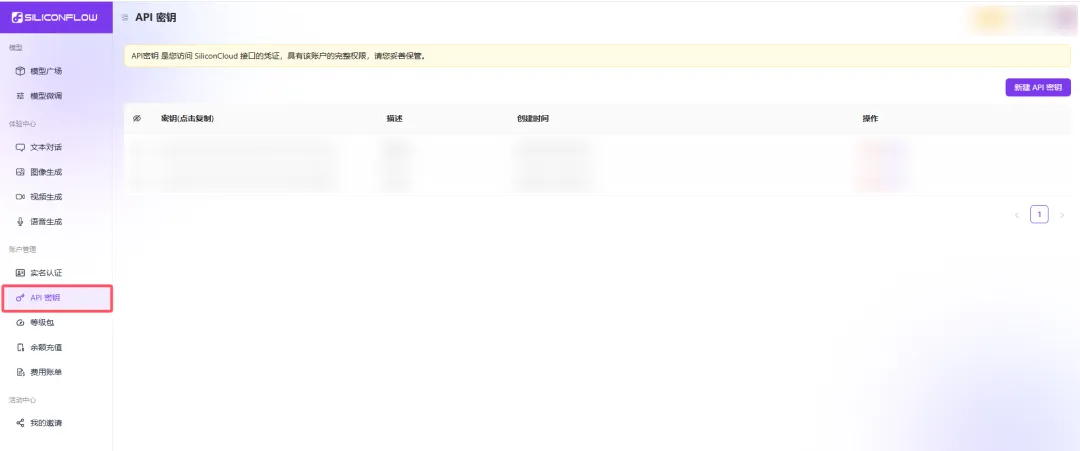
获取钥匙 🔑
-
登录后找到「API密钥」页面
-
点击「创建新密钥」按钮
-
复制生成的密钥(长得像
sk-xxxxxx)
-
💡 小贴士:使用我的邀请码有额外奖励
硅基流动 →
火山方舟 →
📥 安装Chatbox
-
下载对应版本
-
Windows/Mac/全支持
-
-
双击安装 → 保持默认设置
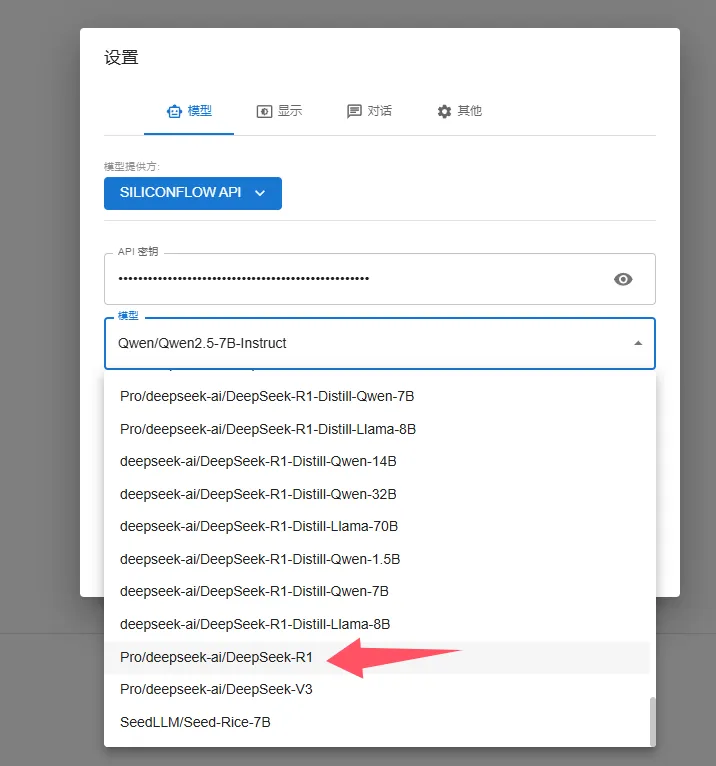
⚙️ 连接API
-
打开Chatbox → 左下角「设置」
-
设置:
[模型供应商] SiliconFlow API[API密钥] 粘贴复制的密钥[模型选择] 下拉框自己选一下
方案2:自建版
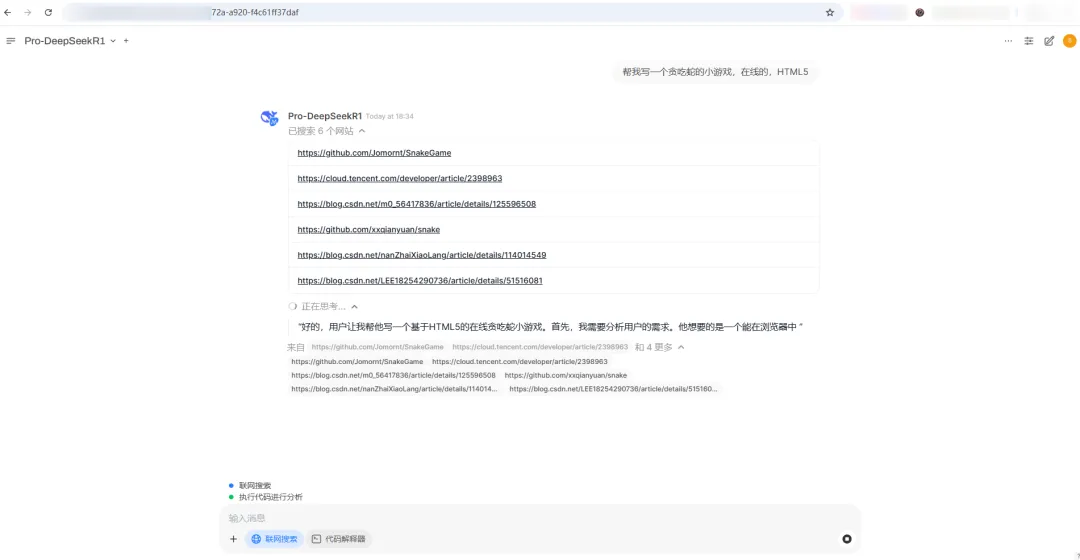
🌈 效果预览
支持联网搜索及思维链完整输出
🖥️ 准备服务器(任选其一)

⚠️ 内存建议≥2GB!
📦 安装
-
安装 Docker
-
安装 Open WebUI
-
安装 SearXNG
🔑 连接大模型
-
浏览器打开Open WebUI
http://你的IP:3000 -
创建管理员账号(记好密码!)
-
进入设置 → 点击「+添加链接」
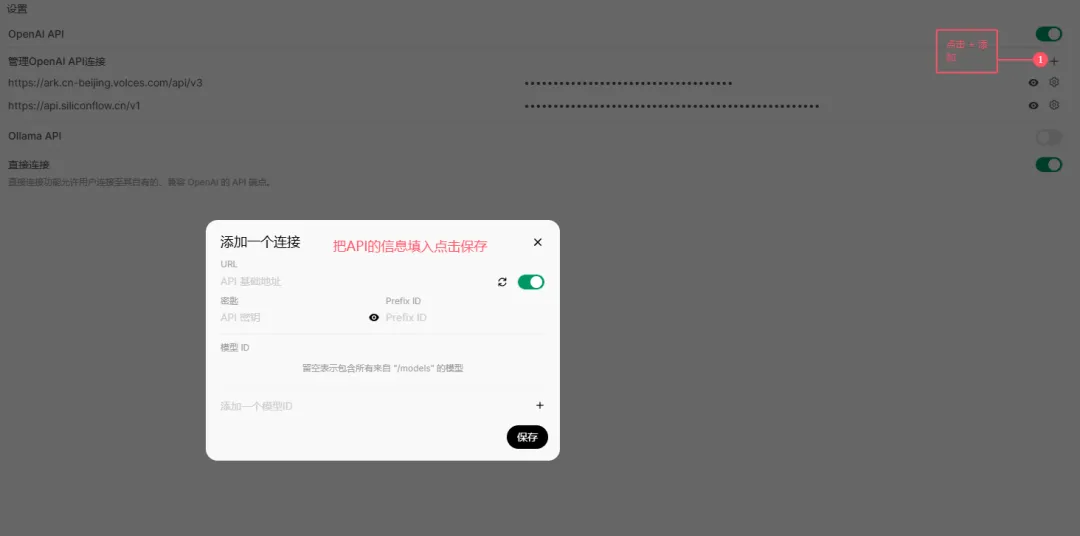
硅基流动的API:https://api.siliconflow.cn/v1
密钥:后台获取
模型:复制模型广场的名称
火山方舟的API:https://ark.cn-beijing.volces.com/api/v3
密钥:后台获取
模型:需要填写在线推理对应模型的ID

🌐 添加联网功能
-
安装搜索工具:SearXNG
-
在Open WebUI设置
[联网搜索] 开启
[searxng的地址] http://你的IP:端口号/search?q={query}
🚨 常见问题
SyntaxError: Unexpected token ‘<’, "<!DOCTYPE "… is not valid JSON
error searching
No search results found
解决方法:
-
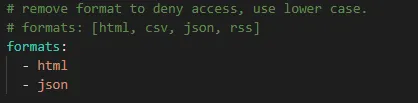
在searxng settings.yml文件里配置一下formats的json输出。(参考下图)
-
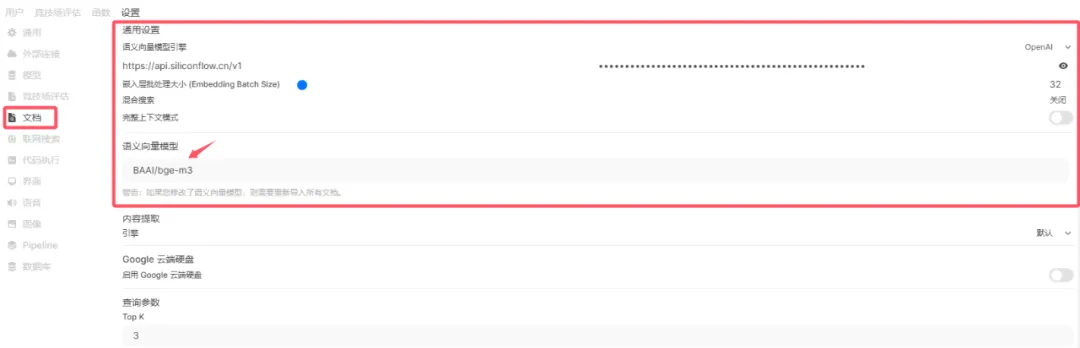
在open webui里设置向量模型;我这里使用的是硅基流动的免费模型。(参考下图)
-
查询URL地址的填写问题。
open webui里使用外部接口会导致思维链不输出的情况,需要借助函数工具。
分享个大佬做的函数工具。
来源:https://openwebui.com/f/zgccrui/deepseek_r1/
函数:其中的API密钥和地址参考教程里提到的内容修改。
"""
title: DeepSeek R1
author: zgccrui
description: 在OpwenWebUI中显示DeepSeek R1模型的思维链 - 仅支持0.5.6及以上版本
version: 1.2.10
licence: MIT
"""
import json
import httpx
import re
from typing import AsyncGenerator, Callable, Awaitable
from pydantic import BaseModel, Field
import asyncio
class Pipe:
class Valves(BaseModel):
DEEPSEEK_API_BASE_URL: str = Field(
default="https://api.deepseek.com/v1",
description="DeepSeek API的基础请求地址",
)
DEEPSEEK_API_KEY: str = Field(
default="", description="用于身份验证的DeepSeek API密钥,可从控制台获取"
)
DEEPSEEK_API_MODEL: str = Field(
default="deepseek-reasoner",
description="API请求的模型名称,默认为 deepseek-reasoner ",
)
def __init__(self):
self.valves = self.Valves()
self.data_prefix = "data:"
self.emitter = None
def pipes(self):
return [
{
"id": self.valves.DEEPSEEK_API_MODEL,
"name": self.valves.DEEPSEEK_API_MODEL,
}
]
async def pipe(
self, body: dict, __event_emitter__: Callable[[dict], Awaitable[None]] = None
) -> AsyncGenerator[str, None]:
"""主处理管道(已移除缓冲)"""
thinking_state = {"thinking": -1} # 使用字典来存储thinking状态
self.emitter = __event_emitter__
# 验证配置
if not self.valves.DEEPSEEK_API_KEY:
yield json.dumps({"error": "未配置API密钥"}, ensure_ascii=False)
return
# 准备请求参数
headers = {
"Authorization": f"Bearer {self.valves.DEEPSEEK_API_KEY}",
"Content-Type": "application/json",
}
try:
# 模型ID提取
model_id = body["model"].split(".", 1)[-1]
payload = {**body, "model": model_id}
# 处理消息以防止连续的相同角色
messages = payload["messages"]
i = 0
while i < len(messages) - 1:
if messages[i]["role"] == messages[i + 1]["role"]:
# 插入具有替代角色的占位符消息
alternate_role = (
"assistant" if messages[i]["role"] == "user" else "user"
)
messages.insert(
i + 1,
{"role": alternate_role, "content": "[Unfinished thinking]"},
)
i += 1
# yield json.dumps(payload, ensure_ascii=False)
# 发起API请求
async with httpx.AsyncClient(http2=True) as client:
async with client.stream(
"POST",
f"{self.valves.DEEPSEEK_API_BASE_URL}/chat/completions",
json=payload,
headers=headers,
timeout=300,
) as response:
# 错误处理
if response.status_code != 200:
error = await response.aread()
yield self._format_error(response.status_code, error)
return
# 流式处理响应
async for line in response.aiter_lines():
if not line.startswith(self.data_prefix):
continue
# 截取 JSON 字符串
json_str = line[len(self.data_prefix) :]
# 去除首尾空格后检查是否为结束标记
if json_str.strip() == "[DONE]":
return
try:
data = json.loads(json_str)
except json.JSONDecodeError as e:
# 格式化错误信息,这里传入错误类型和详细原因(包括出错内容和异常信息)
error_detail = f"解析失败 - 内容:{json_str},原因:{e}"
yield self._format_error("JSONDecodeError", error_detail)
return
choice = data.get("choices", [{}])[0]
# 结束条件判断
if choice.get("finish_reason"):
return
# 状态机处理
state_output = await self._update_thinking_state(
choice.get("delta", {}), thinking_state
)
if state_output:
yield state_output # 直接发送状态标记
if state_output == "<think>":
yield "\n"
# 内容处理并立即发送
content = self._process_content(choice["delta"])
if content:
if content.startswith("<think>"):
match = re.match(r"^<think>", content)
if match:
content = re.sub(r"^<think>", "", content)
yield "<think>"
await asyncio.sleep(0.1)
yield "\n"
elif content.startswith("</think>"):
match = re.match(r"^</think>", content)
if match:
content = re.sub(r"^</think>", "", content)
yield "</think>"
await asyncio.sleep(0.1)
yield "\n"
yield content
except Exception as e:
yield self._format_exception(e)
async def _update_thinking_state(self, delta: dict, thinking_state: dict) -> str:
"""更新思考状态机(简化版)"""
state_output = ""
# 状态转换:未开始 -> 思考中
if thinking_state["thinking"] == -1 and delta.get("reasoning_content"):
thinking_state["thinking"] = 0
state_output = "<think>"
# 状态转换:思考中 -> 已回答
elif (
thinking_state["thinking"] == 0
and not delta.get("reasoning_content")
and delta.get("content")
):
thinking_state["thinking"] = 1
state_output = "\n</think>\n\n"
return state_output
def _process_content(self, delta: dict) -> str:
"""直接返回处理后的内容"""
return delta.get("reasoning_content", "") or delta.get("content", "")
def _format_error(self, status_code: int, error: bytes) -> str:
# 如果 error 已经是字符串,则无需 decode
if isinstance(error, str):
error_str = error
else:
error_str = error.decode(errors="ignore")
try:
err_msg = json.loads(error_str).get("message", error_str)[:200]
except Exception as e:
err_msg = error_str[:200]
return json.dumps(
{"error": f"HTTP {status_code}: {err_msg}"}, ensure_ascii=False
)
def _format_exception(self, e: Exception) -> str:
"""异常格式化保持不变"""
err_type = type(e).__name__
return json.dumps({"error": f"{err_type}: {str(e)}"}, ensure_ascii=False)
在open webui 设置-函数-添加-保存,新建对话-选择模型使用。
💰 费用说明
-
方案1:按对话字数扣费
-
方案2:
-
服务器费用
-
API调用费
-
API接口的费用:
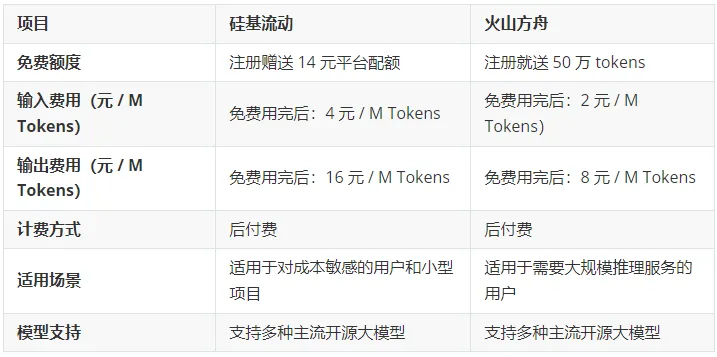
移动端的可以使用腾讯元宝等APP,一样免费快速的体验。
我目前用的方案是Open WebUI+Searxng+Api接口,至于自己部署ollama我觉得没有意义,硬件成本太高,官方开源的满血版都能部署,但跑不起来就没有意义,残血版根本没有搭建的必要。
且Searxng即使不用于Open WebUI对接,也可以当一个搜索引擎来使用。
最后附上硅基流动和火山方舟的邀请链接。
相关文章



